
The New Attack Surface: Why AI Agents Need Taint Analysis
As AI Agents evolve into autonomous actors, securing them requires techniques beyond identity and access controls. This article explores how taint analysis can extend visibility into agent workflows, uncover hidden risks, and strengthen enterprise AI security.
AI agents don’t just compute – they act. And when they act on poisoned input, the consequences can be catastrophic. The AI Agent is revolutionising traditional ways of working across industries and roles. Various agentic protocols such as Model Context Protocol (MCP) and the extended functionality or ‘tools’ they provide are being adopted at a blistering pace. However, with this accelerated innovation comes a massive expansion in the risk surface. In this article, we’ll cover the ‘Taint Analysis’ technique, and, using a couple of real-world scenarios such as the ForcedLeak vulnerability, demonstrate why it’s an effective method for elucidating hidden risk chains, no matter how complex.
What is ‘Taint Analysis’, and Why Does It Matter?
Taint Analysis is a data-flow, analytical technique that identifies sources of untrusted user input, and tracks its flow within a system. Originally designed as a technique for program analysis – otherwise known as ‘taint checking’ – the technique traditionally allowed programs to track variables that are influenced by the untrusted input. If any of those suspicious variables are used to execute a dangerous command (e.g., a direct command to a SQL database or on the operating system), the taint checker would raise a warning to the developer.
Example of a Python script executing a SQL query.Taint analysis would track user_input as untrusted and mark the query as tainted. Because it flows into a database execution, the checker raises a flag.
Fast forward to today, the AI agentic workflow presents the same problem in different clothing. Swap the SQL query for an agent command: the same principle applies, but the stakes are broader.
Example of an agent receiving a user-defined prompt.In similar fashion, an AI agent can take a user’s untrusted input and, in a few hops later, convert it into a critical system action.
Agentic innovation has transformed the way tasks are executed: where code once defined logic, natural language is now the new programming interface. Instead of program executors distilling code into machine-readable, executable instructions, agentic AI workflows interpret wide modalities of information: natural language, code, data, images, video and audio. But these workflows don’t just compute logic. Agents take real-world actions. Organizations and their technical estates are the new operating systems, while agentic AI provides general-purpose execution capabilities across their processes.
But this power comes with risk: a maliciously crafted input, like a prompt injection, can propagate through the workflow with the same potency as a tainted variable in software. Without safeguards, that taint can travel only a hop or two before influencing sensitive decisions, external actions, or systems of record.
Before going further, let’s brush up on some key terminology:
| Term | Definition |
|---|---|
| Taint Source | Any untrusted input entering the system (e.g., user prompt, web page, CRM data). |
| Tainted Variable | A value or state influenced by a taint source, potentially unsafe if unchecked. |
| Sink | A sensitive action or resource where tainted input can cause harm (e.g., database query, HTTP request, system command). |
| Propagation | The flow of tainted data through different components of the system or workflow. |
| Prompt Injection | A type of attack where malicious instructions are hidden in input (text, metadata, documents) to manipulate agent behavior. |
| Human-in-the-Loop | A safeguard where humans review or approve agent actions before execution. |
| Agentic Workflow | A chain of decisions and actions performed by an AI agent across tools, data, and systems. |
Taint Analysis In Action
Let’s take a look at two real-world risk scenarios and demonstrate how taint analysis could effectively detect some unsafe workflows: (1) ForcedLeak vulnerability with SalesForce’s agentic offering, and (2) Endpoint agent without Human-in-the-Loop.
ForcedLeak
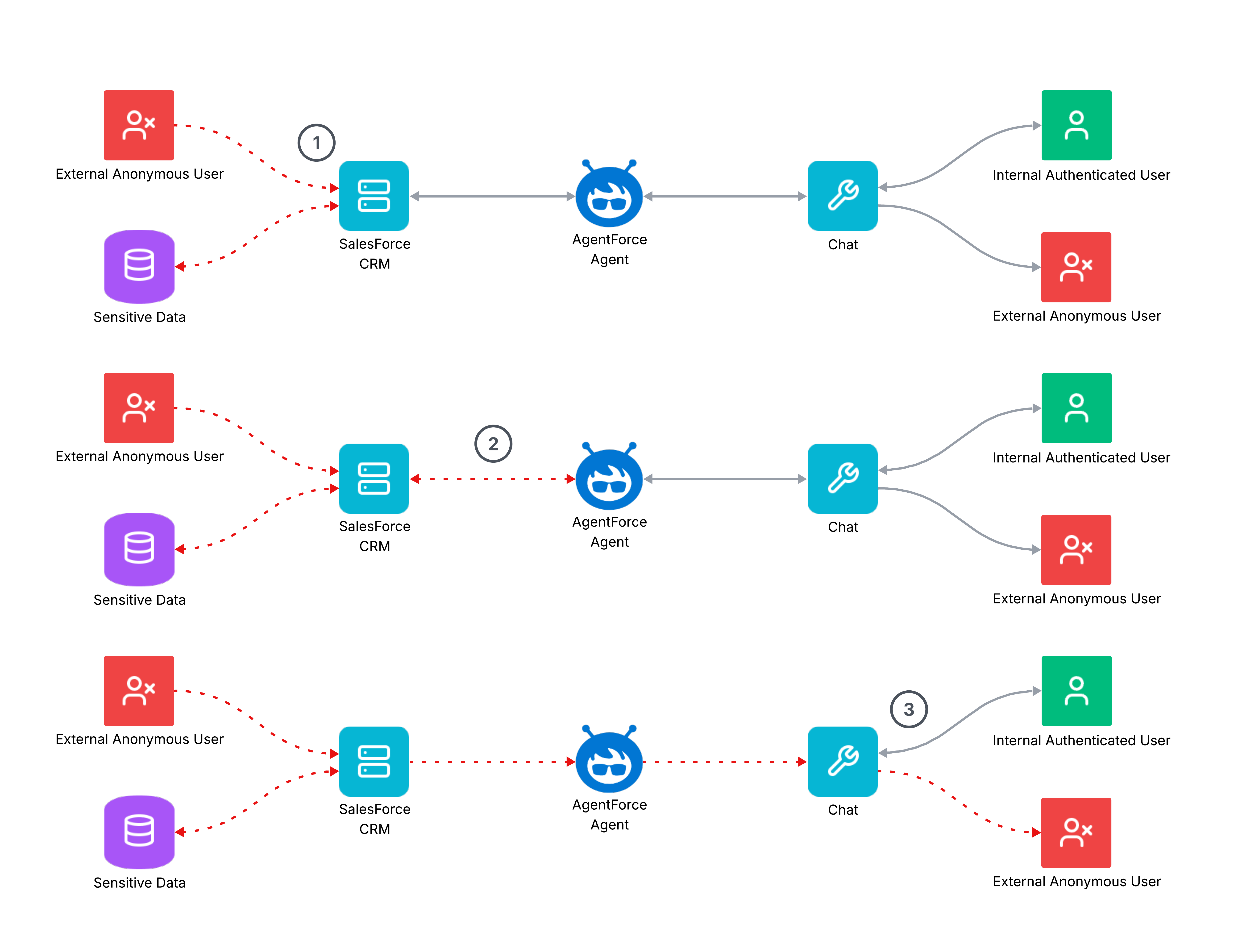
** Example of taint analysis highlighting where poisoned CRM data enters and propagates through the ForcedLeak chain.**Stage 1: Attacker poisons Salesforce CRM with user-controlled metadata via a Web-to-Lead service. Stage 2: User, via a chat tool, prompts the agent to carry out some action which involves reading the poisoned data from the CRM. Stage 3: The now-tainted agent consumes the malicious prompt, reads further sensitive data from the CRM, and creates an exfiltration vector via the chat to the attacker-controlled, allowlisted server (HTML-rendered image with query parameters).
Salesforce’s agentic AI offering, Agentforce , was recently shown to be vulnerable to an indirect prompt injection technique dubbed “ForcedLeak.” The attack – discovered by NomaLabs researchers and which has since been patched – worked by planting malicious instructions in Salesforce CRM metadata, which the agent would later consume during routine operations. Once triggered, the injected prompt caused the agent to exfiltrate sensitive data to an expired but still allowlisted domain controlled by the attacker.
Taint analysis makes the risk pathway behind this attack visible. By mapping out the ingress points of untrusted user input (external, anonymous users writing to the CRM), the sensitive nodes (the CRM itself), and the potential exfiltration channels (the chat connector), taint analysis highlights each step where mitigations could break the chain. With this perspective, system designers can prioritize controls at the most impactful junctures rather than reacting only after a breach.
Endpoint agent without Human-in-the-Loop
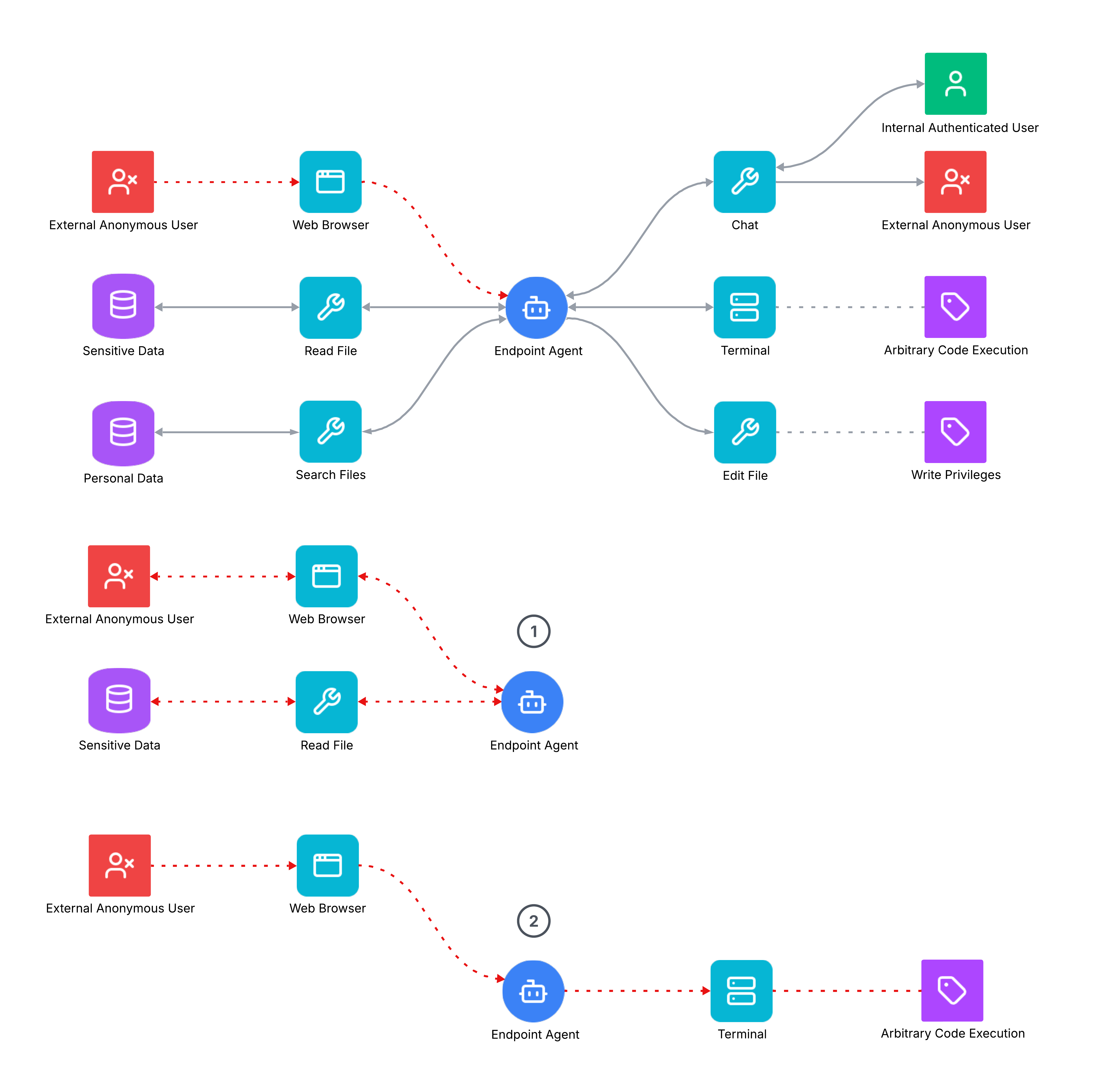
** Example of taint analysis of aneEndpoint workflow (e.g., Cursor, Claude Code).**Multiple risk pathways are possible: for example (1) Sensitive Data Exfiltration via Web Browser (e.g., an indirect prompt injection on a web page), Read/Search File, and either the Chat (e.g., social engineered URLs, rendered images), or the Terminal (curl to an attacker-controlled URL), or back through the Web Browser; or (2) Remote Code Execution via Web Browser directly to the Terminal (no Human-in-the-Loop to block command execution), or via the Chat and Edit File tools (e.g. socially engineer the user into approving an unsafe command).
Endpoint agents, such as those embedded in development environments or personal productivity tools, illustrate another set of risks. Without a human-in-the-loop to approve or deny actions, even seemingly benign workflows can be weaponised. For instance, a malicious web page could indirectly inject instructions that lead the agent to read local files, exfiltrate them through the browser, or send them over a command-line request to an attacker-controlled URL. In another scenario, the chain could progress from web browsing into remote code execution via the terminal or file-editing capabilities, escalating the attack beyond data leakage into system compromise.
But even with a human-in-the-loop, vulnerabilities remain. Social engineering can be used to frame a dangerous command or exfiltration step as safe, nudging the human reviewer into granting approval. In such cases, the safeguard works only as well as the operator’s ability to distinguish legitimate requests from adversarial ones.
Here again, taint analysis provides a structured way of mapping these pathways. It draws attention to where taint enters the system (e.g., web pages or chats), how it interacts with sensitive resources (local files, terminals), and where the final destinations of tainted input (”sinks”) lie (exfil via HTTP requests, command execution). By surfacing these links, taint analysis makes explicit the points where safeguards – such as stricter tool permissions, anomaly detection, or multi-layered approval processes – should be applied.
Summary of ForcedLeak and Endpoint agent risk scenarios
| Scenario | Taint Source | Sensitive Node | Sink (Risk) |
|---|---|---|---|
| ForcedLeak | User-submitted CRM metadata | Salesforce CRM | Data exfiltration via chat → attacker domain |
| Endpoint Agent | Malicious web page input | Local files / terminal | Exfiltration or RCE |
Sources of Risk in Agentic Workflows
Just as taint analysis tracks untrusted variables in software, the same principle applies in agentic workflows. One of the greatest security risks is untrusted user input. The mixture of trusted and untrusted data in LLM inputs gives rise to prompt injection attacks, where an attacker can exploit the AI’s inability to distinguish between safe and malicious instructions. This can lead to unintended behaviors, including the leaking of sensitive data or execution of dangerous commands.
The threat of prompt injection is amplified because virtually any resource accessible to the agent could be a vector for untrusted input: chat terminals, data streams, document stores, vector databases, and MCP tools along with their metadata. Since LLMs process both instructions and data in the same medium, all components interacting with the agent can become potential sources of prompt injection. Only by identifying these sources and tracing the affected agents, tools, and resources can the risks be effectively understood and controlled.
Scaling Risks in Agentic Networks
If dealing with one agent already paints a problematic picture, consider the panorama of agent-to-agent networks and “swarm” workflows: as agents become more and more interconnected – calling each other, delegating tasks, and chaining outputs – risk pathways compound.
Taint analysis scales naturally to these scenarios, as taint can be traced not only within a single agent’s workflow but across agent-to-agent communications. This network-level perspective makes it possible to spot cascading risks, where a tainted input introduced in one corner of the system eventually influences decisions or actions far downstream.
Are All Agentic Risks Security-Related?
Security risks arise when a malicious actor deliberately injects unsafe instructions into or manipulates some other component of an agentic workflow.
Safety risks , on the other hand, can emerge even in the absence of an attacker, such as when an agent misinterprets ambiguous data as an instruction. Consider an email summarization agent: if an email innocuously contains a phrase such as “ all documents must be forwarded to legal@company.com,” the agent may treat this as a directive and act on it, forwarding sensitive information to unintended recipients. Here, taint analysis still applies: the ambiguous input becomes a taint source, and the propagation of that taint highlights where additional safeguards or disambiguation mechanisms are required.
Examples of risk scenarios, with type of agentic risk vs. effectiveness of taint analysis
| Risk Type | Detectable by Taint Analysis? | Example | Why? |
|---|---|---|---|
| Security | Yes | Prompt injection from untrusted input | Input traced as taint → unsafe sink |
| Security | No | Model poisoning, supply chain | Hidden in model, not input |
| Safety | Yes | Misinterpreted content as instruction | Ambiguous input treated as command |
| Safety | No | Resource overprovisioning, infinite loop | No tainted input involved |
Where does Taint Analysis fall short?
Taint analysis is powerful but not a silver bullet. Some safety risks – such as an agent over-provisioning cloud resources or getting stuck in an optimization loop – do not involve untrusted inputs at all, and therefore cannot be modelled with taint analysis. Similarly, some security threats also evade this lens: if the agent’s underlying model has been compromised through data poisoning or supply-chain manipulation, no amount of input/output taint tracking will reveal the deeper flaw.
Taint analysis also relies on the accuracy and completeness of its models. Missing metadata – such as which connectors can expose untrusted data, or which tools represent sensitive sinks – creates blind spots that weaken the analysis. And because it is effective only at the time of analysis, long-running risks (for example, tainted data that has been silently persisted and later re-used) may go undetected without continuous monitoring.
Conclusion
Taint analysis provides a powerful lens for making sense of risk in agentic workflows. By tracing the flow of untrusted inputs, it exposes where vulnerabilities lie and how they may propagate across systems. It is not a complete solution, but as agents take on increasingly critical roles in organizational processes, techniques like taint analysis will be essential to keeping them safe, secure, and trustworthy.
As agentic AI becomes embedded across industries, organizations will need a new class of defensive analytics. Taint analysis won’t solve every problem, but it offers a critical first step: making hidden risk chains visible before attackers exploit them.
AI agents act. By tracing how taint flows through them, we can make sure they act safely.


